Enterprise Data Science, Machine Learning, and AI
Top 10 AI Platform Use Cases For the Enterprise

Accelerate growth efficiently for everyone with the data science and AI experts




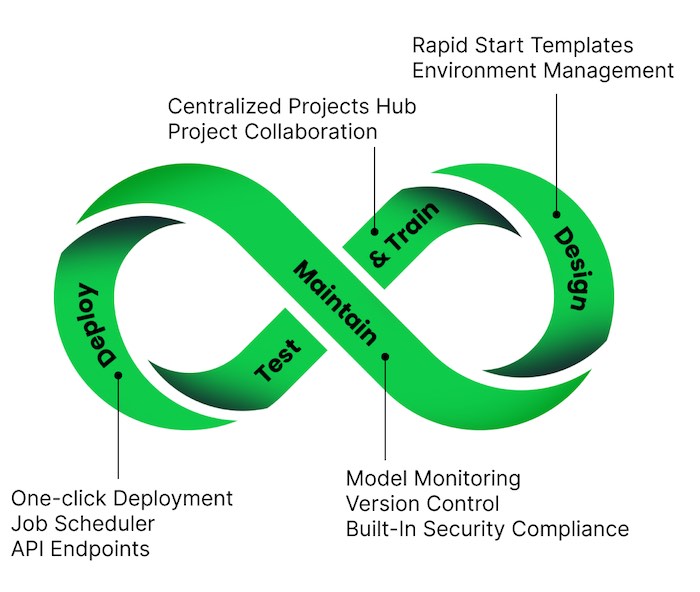
Effortlessly transition from idea to deployment while upholding security standards. Anaconda’s AI and data science platform empowers teams to own the entire project lifecycle—no IT hand-offs, no deployment headaches. Share actionable insights instantly with decision-makers simply by sharing a link to your application.
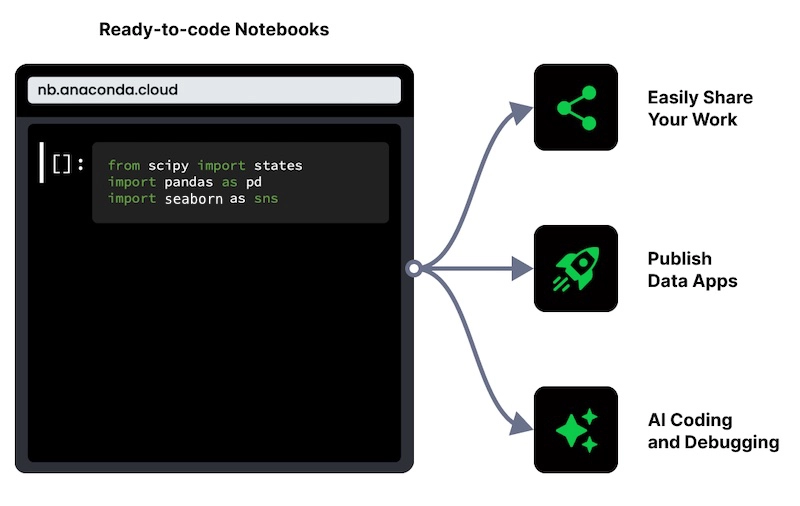
Manage your projects from start to finish with Anaconda’s data science tools. From ready-to-code environments to easy app deployments and an AI-powered coding assistant, Anaconda has everything you need to bring your projects to life.
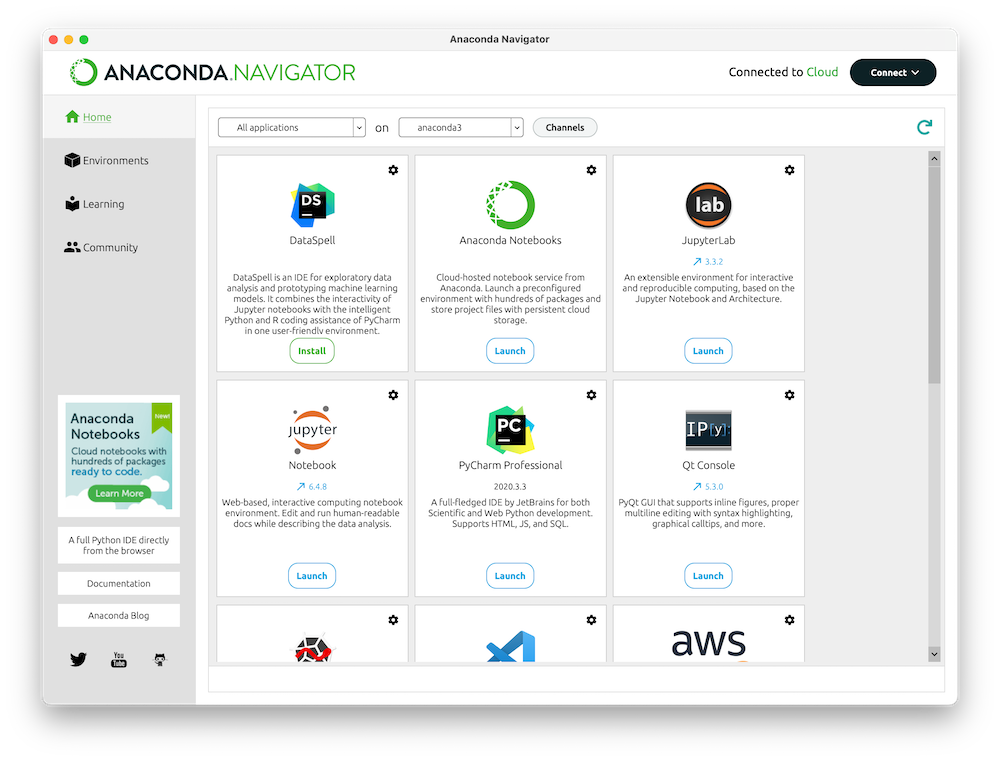
Easily launch AI and data science projects on your local machine with Anaconda Navigator. Take advantage of Anaconda’s extensive open-source package distribution and easy environment management.

We’re not just a trusted partner; we’re the foundation for AI and data science solutions for
industry leading companies like Microsoft, IBM, and Oracle. Our packages and software
support powerful tools such as Python in Excel and a variety of advanced data platforms.


“Anaconda’s conda tool simplifies package and environment management across operating systems. It provides a flexible data science platform with comprehensive package administration and the ability to create separate project environments.”
Julian N. G2 review
“Updating, installing, and deleting libraries becomes very easy.”
Larsen & Toubro Infotech Machine Learning Developer
“Very clean interface. From the start, you can see what you are coding in and what your options are.”
Manhattan Review Data Scientist and Writer
